Dynamic Programming
WARNING!
Note - this is VERY EARLY DAYS! All of the files in the course with this warning are the raw, totally unprocessed notes that I generated during my first reading of “Reinforcement Learning: An Introduction”.
I’ll be converting these into proper course sections with wonderful embedded code that you can try out. I’m not there yet, but I wanted to develop all of this in the open.
Maybe you’ll find these notes interesting, but don’t expect anything special… yet!
Notes
Dynamic Programming! Remember to stress that we’re just exploring how to flex the various variables:
- world model, dynamics
- policy
- value function (state or action)
This fixes the world model, which lets us explore the others.
This also introduces the idea of “bootstrapping”, that we start with something random, or initialized to constants, and then use estimates to update other estimates. The term’s defined on page 89.
Notes
Methods for solving MDPs if we have perfect models. A perfect model means, we know exactly what the odds are of where we’re going to progress as the result of an action. What if we know the dynamics of the system?
(Remember - the whole goal of the reinforcement learning BOOK is to show that all of these pieces can be fiddled with independently. That is why we’re going through all of this, flexing our RL muscles. What is the point of each piece?)
God, I hated that term, Dynamic Programming. But now I get it!
BACKGROUND ON THE TERM: https://en.wikipedia.org/wiki/Dynamic_programming#History He was trying to be impressive and capture the idea that this was about capturing dynamics. Obvious I guess.
This is a way of isolating the problem of… let’s say we know exactly what’s going to happen. Actually, this totally makes sense for something like checkers or chess. We absolutely know, and can play forward in our minds, what the result of each move is going to be. There is no uncertainty even!
Or you might have something with a dice roll, with some randomness. That’s fine, you know how the die works. No problem at all.
Anyway. Once you have the dynamics, this section is about how to compute optimal value functions.
Policy Evaluation, or the Prediction Problem
- iterative policy evaluation, p. 74 - start with something random and start building up by walking around according to the dynamics and updating.
- then do you use two arrays? Or just GET SOME!
- You’re sweeping through the state space… do you visit everything or are there some states that just don’t matter that much?
You accept as input some policy to be evaluated. This will never change. Then you go walk around the state space, updating the value to be the reward you’d get, averaged across
- all actions you could take, weighted by their probability
- all states and rewards you might end up in or receive from the environment, based on THEIR probability… which is of course totally known.
- Loop a ton of times until you have this wonderful estimate of the value function, for any state, of the policy you showed up with.
This will converge in the limit, but in practice… you just stop and choose some parameter.
Policy Improvement
What changes here?
The goal is to make better policies, of course, as hinted at in chapter 3… not just evaluate ones that we already know about.
introduce the idea of $q_{\pi}(s, a)$, what happens when you FIRST select one action… and then thereafter follow the old policy.
Turns out it is always better to follow the best action locally. And then that gives you a better overall policy, and you can keep iterating on that.
This is called the Policy Improvement Theorem and always results in a better policy… p. 78-79
The process of making a new policy that improves on an original policy, by making it greedy with respect to the value function of the original policy, is called policy improvement. (p. 79)
So how to make the best policy? Once you know the value function for all states of some given policy… go through for each state and update the policy to choose the action that gives you the MAX value for that state.
All of the information about the future is in that value! This will always work!
But it’s going to take a ton of time between these updates, since you have to go back and do it again.
Policy Iteration
Oh, boom, go back and do it again. Will you get any better? Yes, of course you will. And trading back and forth is called, boom, policy iteration.
This If you ping back and forth you’re going to end up with a monotonically increasing series of policy evaluation and improvements, better policies…
This is called policy iteration.
Value Iteration
Eventually you’re going to converge to the best, but even in the above examples, we’ve introduced a parameter that stops convergence and just moves the fuck on.
How effective can that be? What if we just did a SINGLE STEP before updating the policy?
This is called value iteration. The code on page 83 bakes in the policy by no longer taking a policy at all, but just by default choosing the max. This means that the “policy update” is now just a function - max across all actions available at a given state - instead of a thing you have to specifically store.
Well, it turns out that these are the two limiting cases, but you can totally play between the two.
- Stop at some convergence, OR
- stop evaluating after a number of steps.
That’s what we’re dealing with here, and that’s what we should bake into the interface.
Because the max operation in (4.10) is the only difference between these updates, this just means that the max operation is added to some sweeps of policy evaluation.
All of these converge!
Async Dynamic Programming
Seductive name, I like it.
This is what happens when you relax the idea that you need to go over the entire state space at once, in a big sweep. What happens if you allow random orders? Allowing some state to be updated multiple times, even?
This doesn’t necessarily make things cheaper… but it helps us with the idea that we can start to focus in on specific states.
Maybe we start near the end of the game? Close to the end state, if we’re on a game board and have some other metric of how close we are to the finish? Well, that is tough to calculate.
Woah, maybe we run the whole thing as the agent is playing! Maybe we have some particular start state?
Asynchronous algorithms also make it easier to intermix computation with real-time interaction. To solve a given MDP, we can run an iterative DP algorithm at the same time that an agent is actually experiencing the MDP. The agent’s experience can be used to determine the states to which the DP algorithm applies its updates. At the same time, the latest value and policy information from the DP algorithm can guide the agent’s decision making. For example, we can apply updates to states as the agent visits them. This makes it possible to focus the DP algorithm’s updates onto parts of the state set that are most relevant to the agent. This kind of focusing is a repeated theme in reinforcement learning. (p. 85)
Generalized Policy Iteration
This is the model we presented before, when we just let them interact, improvement and evaluation, and assume that everything is going to be just fine. We’ve already touched on this, but this section is about showing that that will converge.
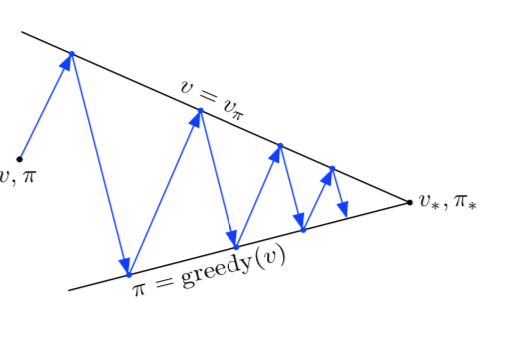
application dependent, how you tune this stuff… or you could trust some other learning process to handle it.
Programming Exercises
- Show the interface for the world, and then tic-tac-toe or something as an example of a game that you can roll forward.
- Write a function that implements the idea of policy evaluation
- policy improvement
- policy iteration
- value iteration
- the overall thing, the overall interface, that allows you to tune when to stop, after a number of steps or after some delta. You take a stopping function, basically and you’re able to kick back the result.
- Oh, we also want to have some way of choosing what state comes next…
All of these are great ideas and showing how they can just be a function is very nice.
And show off that the goal is a function that produces a value function AND how you’re going to approach it. You want a policy with justification, basically.